Computadoras sobre ruedas. Así es como la gente ve los coches actualmente. Prácticamente todo lo que sucede en un vehículo es monitoreado y accionado por un microcontrolador, desde abrir las ventanas hasta calcular la mezcla óptima de aire y combustible para la demanda de torque actual. Pero la superficie apenas ha sido arañada en términos de cuánta potencia informática está llegando a los vehículos.
Subida de vehículos autónomos L3 y robotaxis
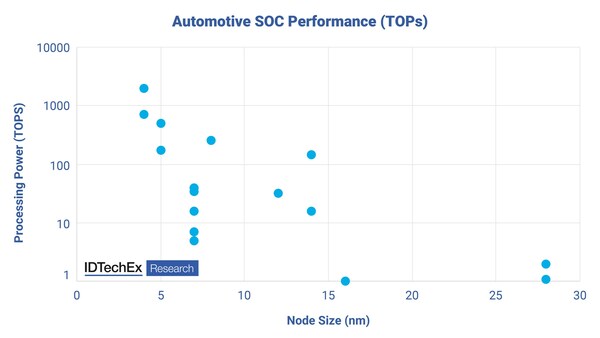 Rendimiento del SOC automotriz (TOP). Fuente: IDTechEx
Rendimiento del SOC automotriz (TOP). Fuente: IDTechExLa era del transporte autónomo está amaneciendo y con ella traerá una nueva era de requisitos computacionales para la industria automotriz. Los automóviles automatizados requieren amplios conjuntos de sensores para escanear el entorno y proporcionar al automóvil los datos que necesita para emular la conducción humana. El informe " Automóviles autónomos y robotaxis 2024-2044 " de IDTechEx encontró que los principales robotaxis SAE nivel 4 tienen hasta 40 sensores individuales. Combinado con el próximo lanzamiento de tecnologías automatizadas en el mercado de vehículos, esto impulsará una tasa compuesta anual del 13% en 10 años en el mercado de sensores automotrices. Sin embargo, los sensores por sí solos son casi inútiles sin que una informática de alto rendimiento procese sus datos y construya una representación 3D del entorno para informar la política de conducción programada del vehículo.
La informática de alto rendimiento (HPC) toma la salida de datos en tiempo real de una serie de sensores y realiza varios procesos importantes. Dos desafíos clave que enfrenta son la fusión de sensores y la clasificación de objetos, y existe cierto desacuerdo en cuanto al orden en que se realizan. Algunos piensan que lo mejor es la fusión temprana, en la que todos los datos de los sensores se combinan en una representación 3D de la escena, y luego un algoritmo de IA, ejecutado por la unidad HPC del vehículo, identifica y etiqueta cada objeto detectado. Otros piensan que se debería generar una lista de objetos a partir de cada sensor y luego fusionar los resultados. Esto tiene la ventaja de poder cruzar las detecciones de cada sensor y comprobar su concordancia. Sin embargo, la desventaja de esto son los desafíos a la hora de manejar las discrepancias entre las listas de objetos de diferentes sensores.
El SOC de computación autónoma
Ya sea que se utilice fusión tardía o temprana, HPC todavía tendrá mucho procesamiento de datos por hacer en forma de procesamiento de imágenes y ejecución de algoritmos de inteligencia artificial para la clasificación de imágenes y la política de conducción. Los componentes clave que manejan estas tareas son los procesadores gráficos (GPU), los procesadores computacionales (CPU) y la RAM. Normalmente, se trata de componentes discretos separados; sin embargo, los requisitos específicos de HPC para los coches autónomos han llevado a que se combinen en chips únicos llamados SOC o sistemas en chips. Estos combinan GPU, CPU, RAM y más en una sola pieza de silicio. El SOC ideal puede tomar datos de todos los sensores de conducción autónoma del vehículo, procesarlos, identificar y clasificar todos los objetos detectados y crear un conjunto de actuaciones de dirección, acelerador y freno de acuerdo con la política de conducción. Así, el SOC es responsable de todo el sistema de conducción autónoma.
Poner todas estas características en un solo chip es clave para cumplir con los requisitos computacionales de la conducción autónoma. Con una separación física casi nula, cada parte del chip puede intercambiar datos con una latencia casi nula, casi sin ruido y con un ancho de banda enorme. Esto se opone a tener componentes discretos distribuidos en una PCB, con más interfaces y más rastros de datos que introducen ruido y latencia.
Las GPU son una parte clave del rompecabezas; sus capacidades de procesamiento de imágenes, combinadas con su idoneidad para ejecutar algoritmos de inteligencia artificial a través de aprendizaje profundo y redes neuronales, los convierten en una piedra angular del SOC. Es por eso que vemos a Nvidia ganando terreno en el espacio de los vehículos autónomos. Tiene una larga trayectoria en el desarrollo de GPU para aplicaciones gráficas en informática y ha podido dar un giro, aportando su experiencia a la industria automotriz. Sus plataformas Xavier y Orin han sido fundamentales en el procesamiento computacional de vehículos autónomos.
Mobileye es otro que ha sido pionero en esta industria. Fundada en 1999, rápidamente causó una impresión y un nombre, atrayendo el interés de Intel y conduciendo a una adquisición. Ahora vuelve a ser público y ha llegado a muchos vehículos de consumo que utilizan aplicaciones ADAS.
Mobileye y Nvidia han estado aumentando su poder de cálculo recientemente, pasando de unos pocos TOPS (operaciones terra por segundo) a decenas de TOPS, ahora cientos de TOPS, y apuntando a miles de TOPS. La principal forma en que se producen estas mejoras es mediante la adopción de tamaños de nodos cada vez más pequeños de fundiciones líderes como TSMC y Samsung. Han estado persiguiendo estas mejoras a través de tecnologías de nodos más pequeños de sus fundiciones de apoyo.
Tecnologías de semiconductores en crecimiento
En los últimos años, IDTechEx ha visto a Mobileye, Nivida y otros pasar de 28 nm en 2018 a soluciones FinFET de 7 nm y menos en 2021. Sin embargo, las fundiciones ahora están produciendo tecnologías de menos de 5 nm y se dirigen hacia tecnologías de menos de 1 nm en el futuro. IDTechEx ha observado que cada vez que la tecnología de nodos se reduce a la mitad, la potencia de cálculo aumenta en un factor de 10. Una relación que se encuentra y se muestra explícitamente en el informe " Semiconductores para coches autónomos y eléctricos 2023-2033 " de IDTechEx. Pero perseguir tamaños de nodos cada vez más pequeños será cada vez más costoso. Una sola oblea de 300 mm de tecnología de 3 nm de TSMC cuesta alrededor de 20.000 dólares estadounidenses , y ese precio seguirá creciendo a medida que se demanden tecnologías inferiores a 3 millones en una variedad de industrias, desde aplicaciones informáticas normales como teléfonos, portátiles y PC, hasta la nueva demanda procedente del sector de la automoción.
Como tal, los desarrolladores de HPC para automóviles deben pensar en cómo optimizar las tecnologías existentes para obtener el máximo rendimiento. Un enfoque que IDTechEx está viendo es un mayor enfoque en la inteligencia artificial (IA), las redes neuronales (NN) y los aceleradores de aprendizaje profundo (DL). Estos utilizan nuevas estrategias de procesamiento de datos mejoradas por IA, lo que reduce la dependencia de los enfoques clásicos que se encuentran en la GPU. Esto puede aumentar el rendimiento del chip a un precio muy bajo, requiriendo menos inversión en tecnologías de nodos más pequeños e incluso produciendo un beneficio de eficiencia general. IDTechEx está viendo que la IA se vuelve más común en los diagramas de bloques SOC de los principales niveles 2 como Mobileye y Renesas. Pero una perspectiva particularmente interesante es Recogni. Recogni es una nueva empresa que ha desarrollado un acelerador de inteligencia artificial para aplicaciones SOC de conducción autónoma que promete eficiencia y potencia computacional revolucionarias.
Incluso con la reducción del tamaño de los nodos y las soluciones imaginativas de IA, la industria más grande de chips informáticos todavía está experimentando una desaceleración en el ritmo de desarrollo. La ley de Moore dice que el poder computacional debería duplicarse cada dos años, una fórmula empírica de décadas de antigüedad que se ha mantenido vigente hasta hace poco. Algunos dicen que la ley de Moore está empezando a desacelerarse a medida que la industria enfrenta desafíos tecnológicos cada vez más difíciles para lograr ganancias incrementales cada vez más pequeñas. Otros dicen que la ley de Moore está muerta.
Una solución destacada para hacer frente a la desaceleración de la Ley de Moore y el aumento sustancial del coste de fabricación de los circuitos integrados monolíticos (CI) es el concepto de "chiplets". El concepto central de los chiplets implica deconstruir un CI monolítico en distintos bloques funcionales, transformar estos bloques en chiplets separados y, posteriormente, volver a ensamblarlos a nivel de empaque. El objetivo final de un procesador basado en chiplets es mantener o mejorar el rendimiento y al mismo tiempo reducir los gastos generales de producción en comparación con los circuitos integrados monolíticos tradicionales. La eficacia del diseño de chiplets depende en gran medida de las técnicas de empaquetado, en particular las empleadas para interconectar múltiples chiplets, ya que tienen un impacto significativo en el rendimiento general del sistema. Estas tecnologías avanzadas de empaquetado de semiconductores, que abarcan enfoques como 2,5D IC, 3D IC y empaquetado a nivel de oblea de alta densidad, se denominan colectivamente "empaquetado de semiconductores avanzado". Estas técnicas de vanguardia se examinan exhaustivamente en el informe de investigación de IDTechEx titulado " Embalaje de semiconductores avanzado 2022-2032 ". Facilitan la convergencia de múltiples chiplets, a menudo producidos en diferentes nodos de proceso, en un único sustrato. Esta convergencia es posible gracias a la utilización de tamaños de relieve compactos, lo que permite mayores densidades de interconexión y capacidades de integración superiores.
Si observamos el panorama actual de las tecnologías avanzadas de empaquetado de semiconductores en la industria, tomemos el sector de CPU para servidores como ejemplo ilustrativo. Si bien la mayoría de las CPU de servidor contemporáneas se basan en diseños monolíticos de sistema en chip (SoC), han surgido desarrollos notables. En 2021, Intel anunció su próxima CPU para servidor, Sapphire Rapids, que adoptará un enfoque novedoso. Esta CPU de próxima generación se construirá como un módulo de cuatro chips interconectados a través del Embedded Multi-die Interconnect Bridge (EMIB) de Intel, que representa una solución avanzada de empaquetado de semiconductores 2.5D.
Al mismo tiempo, AMD ha adoptado el poder de las técnicas avanzadas de empaquetado de semiconductores 3D para mejorar el rendimiento de la CPU del servidor. En el caso de su última CPU para servidor, Milan-X (lanzada en marzo de 2022 ), AMD emplea una estrategia de empaquetado 3D que implica apilar una unidad de caché directamente encima del procesador. Esta innovación da como resultado un notable aumento de >200 veces la densidad de interconexión en comparación con el empaquetado 2D convencional, según afirma AMD. Estos desarrollos no se limitan únicamente a las CPU; El ámbito de los centros de datos también ha sido testigo de la integración de tecnologías avanzadas de empaquetado de semiconductores para otros componentes, como los aceleradores. NVIDIA, un actor clave, ha estado utilizando la tecnología de empaquetado 2.5D de TSMC conocida como Chip on Wafer on Substrate (CoWoS) para sus aceleradores GPU de alta gama desde 2016.
Este aumento de adopción, ejemplificado tanto por Intel como por AMD en sus productos de vanguardia, apunta a una utilización cada vez mayor de tecnologías avanzadas de empaquetado de semiconductores en toda la industria. La tendencia va más allá de las CPU de servidores y abarca una variedad de componentes de centros de datos. A medida que evoluciona el panorama de la industria, estas innovadoras metodologías de embalaje están preparadas para desempeñar un papel fundamental en la mejora del rendimiento, la integración y la eficiencia.
En el futuro previsible (en un lapso de 10 a 15 años), impulsado por los crecientes requisitos de procesamiento y la necesidad de un ancho de banda sustancial con un consumo de energía mínimo, el sector automotriz emulará una trayectoria similar a la de la nube y la computación de alto rendimiento ( HPC) mercado. Esta trayectoria implica la integración de diversos elementos de propiedad intelectual (PI) y silicio a nivel de paquete para lograr características esenciales y un rendimiento óptimo. En el contexto de los procesadores informáticos de vehículos autónomos (AV), el panorama de los envases será testigo de la fusión de múltiples componentes de silicio dentro del mismo paquete, implementando enfoques avanzados de diseño 2,5D y 3D.
Con la creciente demanda de informática de alto rendimiento en los vehículos y la necesidad de un crecimiento continuo del rendimiento, habrá una rápida evolución en la tecnología utilizada en las computadoras para automóviles. Los tamaños de nodos inferiores a 3 nm, los diseños de chiplets, la mayor dependencia de la aceleración de la IA, el empaquetado 2,5D e incluso el empaquetado 3D se convertirán en una parte normal de HPC para las tecnologías autónomas en los automóviles. Las computadoras han estado en los automóviles durante décadas, pero las tecnologías que se avecinan harán que un automóvil promedio de hoy parezca una tecnología de línea fija en un mundo de teléfonos inteligentes.
Para más información en esta área consulte " Semiconductores para Coches Autónomos y Eléctricos 2023-2043 ", " Coches Autónomos, Robotaxis y Sensores 2024-2044 " y " Embalaje de Semiconductores Avanzado 2023-2043 ". IDTechEx también ofrece datos y análisis dirigidos por expertos sobre estos temas como parte de una suscripción a inteligencia de mercado; obtenga más información en www.IDTechEx.com/Subscriptions .
Compartiendo este artículo usted puede ayudar a difundir valor a otros que están buscando este tipo de información. Si valora el trabajo que hacemos en Valenciacars para usted y le resulta útil, le queremos pedir un gran favor: por favor comparta el artículo en WhatsApp, en Facebook , en Twitter y sus demás redes
IDTechEx analiza la computación de alto rendimiento para automoción que hace que los coches sean Computadoras sobre ruedas.
Comentarios
Publicar un comentario